The Localized Feature Selection Method (LFS)
Conventional feature selection methods for machine learning problems all select a single (global) set of features that applies uniformly over the sample space. In contrast, the LFS method [1,2] selects a unique (and generally distinct) set of features for every sample in the training set. This allows the LFS method to adapt to irregular boundaries between the classes and thus offer improved performance over conventional methods.
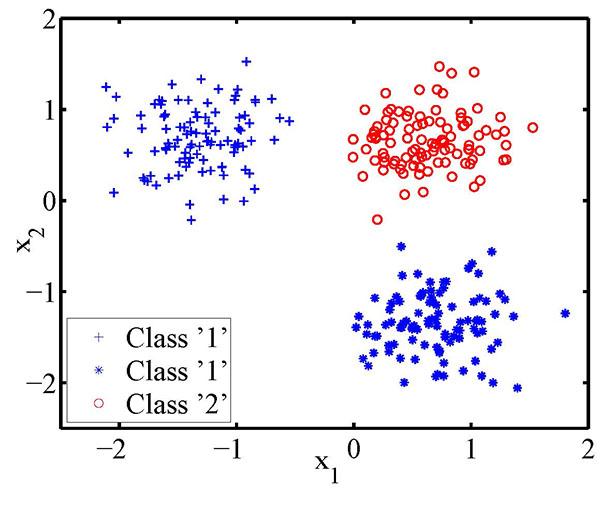
By way of comparison, deep learning methods are capable of extracting useful features directly from the raw data. However, they require large amounts of training data. These methods are difficult to train due to problems with local minima. In contrast, the objective function of the LFS method is formulated as a linear program and hence it is computationally efficient, and its solution always corresponds to the global optimum. Further, the LFS method is well suited to the “data poor” case where the number of candidate features far exceeds the number of available training samples. The LFS method is also immune to the overfitting problem and can accommodate the situation where the boundaries between the classes are arbitrarily complex. In this latter respect, the following figure shows a synthetic data set where one of the classes is disjoint, yet the LFS method classifies this problem with 100% accuracy.
Matlab code for the LFS method is available at https://github.com/armanfn/LFS
[1] Narges Armanfard, James P. Reilly, Majid Komeili, “Local Feature Selection for Data Classification”, IEEE Trans, Patten Analysis and Machine Intelligence, Vol. 38, No. 6, 2016, pp. 1217-1227.
[2] Narges Armanfard, James P. Reilly, Majid Komeili, “Feature Selection and Classification Based on Local Modeling of the Sample Space”, IEEE Trans. Neural Networks and Learning Systems, Vol. 29, No. 5, May 2018, pp. 1396-1413 DOI: 10.1109/TNNLS.2017.2676101.
Machine Learning Analysis of the EEG for Characterization of Disorders of Consciousness
We are using machine learning analysis of the EEG to characterize coma, concussion, and other disorders of consciousness. As an example, Prof. John Connolly, myself and others have secured a major CHRP grant from the Canadian government that is funding a study using the odd-ball paradigm to assess severity of coma. With this paradigm, short auditory tones (stimuli) are presented repetitively to a subject. Rare (deviant) tones are interspersed with more frequently occurring standard tones. Deviant tones can differ in loudness, frequency or duration. Recent work [3] has shown that if a comatose patient exhibits the mismatched negativity (MMN) component in the EEG response to a deviant stimulus, the patient is highly likely to emerge. However, the MMN component is very difficult to detect, resulting in a test with low sensitivity. Former PhD student Dr. Narges Armanfard (now a faculty member of the ECE Department at McGill) developed a novel machine learning method called the localized feature selection (LFS) method [1,2 above] that is highly effective at performing this task. Further details are in [4].
The figure below shows the similarity of a coma patient’s responses to those of healthy controls, vs. a time index. The similarity measure is a product of the LFS algorithm. A unit increment of 1 on the time scale corresponds to a time interval of approximately two minutes. From this figure, it is apparent there are intervals where the similarity is high, implying that the patient’s responses closely resemble those of healthy subjects, further implying the patient exhibits the MMN and therefore that the patient should emerge. This patient did in fact emerge, in spite of the fact that visual inspection of the patient’s ERP waveforms showed no evidence of the MMN.
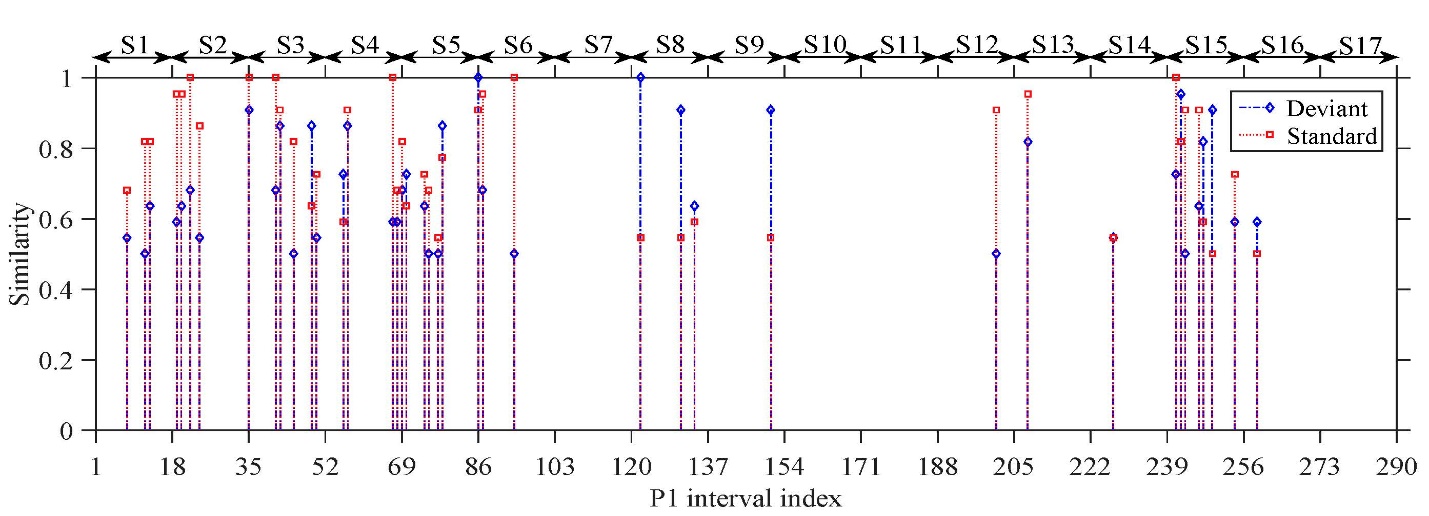
Also evident from this figure is that the similarity measure waxes and wanes with time – i.e., the patient’s level of consciousness varies with time. This is a new finding that was revealed only through the use of advanced machine learning methods.
[3] Fischer, C., Morlet, D., Bouchet, P., Luaute, J., Jourdan, C., & Salord, F. (1999). Mismatch negativity and late auditory evoked potentials in comatose patients. Clinical neurophysiology, 110(9), 1601-1610.
[4] Narges Armanfard, Majid Komeili, James P. Reilly, John F. Connolly, “Automatic and Continuous Detection of Mismatch Negativity: Application to Coma Outcome Prediction”, IEEE Journal of Biomedical and Health Informatics, Vol. 23, No. 4, April, 2019 pp. 1794 - 1804 DOI: 10.1109 JBHI.2018.2877738.
Machine Learning Based on the Electroencephalogram (EEG) for Applications in Neuroscience and Psychiatry
The Research Team

The collaborators on this research effort are, from left to right, (standing): Dr. Gary Hasey, MD, Dept. of Psychiatry and Behavioural Neuroscience (PBN) McMaster, Prof. J. Reilly, Dept of ECE, McMaster, Dr. Ahmad Khodayari, Etherton Fellow in the Dept. of PBN, and Dr. Hubert de Bruin, ECE, McMaster. Not shown is Dr. Duncan MacCrimmon, MD, Dept. of PBN.
Machine Learning for Major Depression
Major depressive disorder (MDD) is a serious and common mental disorder and is a major cause of workplace disability, with costs very similar to those of diabetes and heart disease. By the year 2020, depression is expected to account for about 15% of total global disease burden, second only to ischemic heart disease. In industrialized countries mental illnesses may account for about 16% of total health care costs and for about 30% of disability claims.
There are approximately 22 available anti-depressant medications for the treatment of MDD that are divided into four classes. Each class functions by altering levels of particular neuro-transmitters in the brain. Despite the severity and extensiveness of MDD, objective procedures for selecting which of these medications is optimal for a specific individual are lacking. Therefore the psychiatrist, when treating MDD, must by necessity resort to a trial-and-error procedure to determine an effective treatment. Typically 60 to 70% of those treated do not remit after the first antidepressant medication trial. Although about 67% will eventually reach remission, up to 4 different antidepressant treatment trials may be required, each taking 6 weeks or longer. The personal and economic cost of delayed or ineffective therapy is substantial, in that in the interval required to reach remission, the patient is likely to be disabled, unable to work, prone to suicide, and suffer intensely.
The objective of this project is to develop machine learning (ML) methods that can predict the response of a particular subject to various therapies for MDD, before treatment begins. The ML methods are based on analysis of the subject's pre-treatment, resting EEG, perhaps complemented by additional biomarkers. The successful development of such a facility will have a major disruptive effect in the practice of psychiatry, since it will significantly improve the chances of an effective treatment being prescribed in the first instance.
Results: So far, we have developed prediction models, based on pilot study data, to predict response to SSRIs (selective serotonin reuptake inhibitors, which are a commonly prescribed form of anti-depressant medication), and to repetitive transcranial magnetic stimulation (rTMS), which is a new, non-invasive form of therapy for the treatment of MDD. We have also developed similar models for prediction of response to the anti-psychotic drug clozapine, which is very effective in treating schizophrenia. Our prediction accuracies in each case are 80% or better.
Current research in this area involves the development of new machine learning methods for this application. Specifically, we are investigating the use of brain source localization methods, improved methods for feature selection and classification, as well as improved kernelization techniques to improve the robustness and accuracy of our predictions.
With financial support from Magstim Ltd., Carmarthenshire, Wales, we are currently in the process of expanding the extent of the available training base, and extending the machine learning prediction approach to a broader range of therapies for MDD.
We are also extending machine learning methodology to perform diagnosis of psychiatric illness, based on the subject's resting EEG.
Related research publications:
- Diagnosis of Psychiatric Disorders Using EEG Data and Employing a Statistical Decision Model
- Using Pre-treatment EEG Data to Predict Response to SSRI Treatment for MDD
- Machine Learning Methodologies Using Pre-Treatment Electroencephalography Can Predict The Symptomatic Response To Clozapine Therapy
This work was featured in a March 2011 IEEE spectrum article: The psychiatrist in the machine.
More detail on this work is available in this PowerPoint presentation.
Application of Machine Learning in Neuroscience
The machine learning prediction methods discussed above have been extended to the determination of the age of infants, based on their event-related potentials in response to an audio stimulus. Infant age can be categorized into 6-month old, 12-month old, and adult classes. The method can be used to evaluate the chronological age vs. the “neurological age” of an infant, thereby indicating potential developmental delay.
Proposed research in this area involves the use of brain source localization methods to determine the neurological space-time response to various stimuli. The objective is to provide deeper insight into how the brain processes input stimuli.
Related research publication: A Machine Learning Approach for Distinguishing Age of Infants Using Auditory Evoked Potentials